

Back for Day 2! Today was another relatively easy problem. So I am going to take the time to talk about another cool thing on AoC that I love.
If you go to the AoC site now, you will see the problems in a big list as a bunch of hashes and @ symbols.
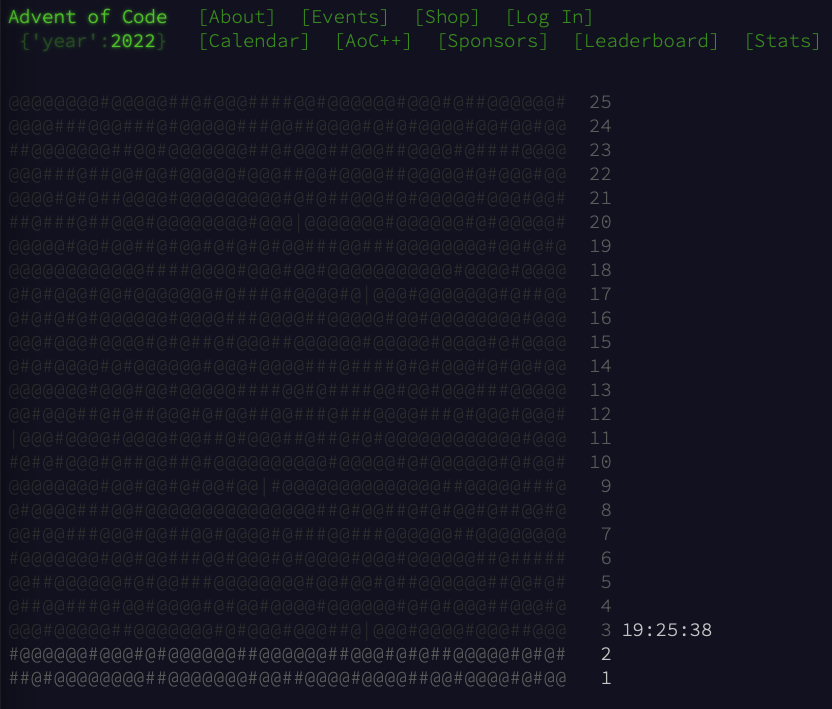
As you complete each day, you unlock these lines, which upon completion form an awesome ASCII Art image. Here is what we have so far:
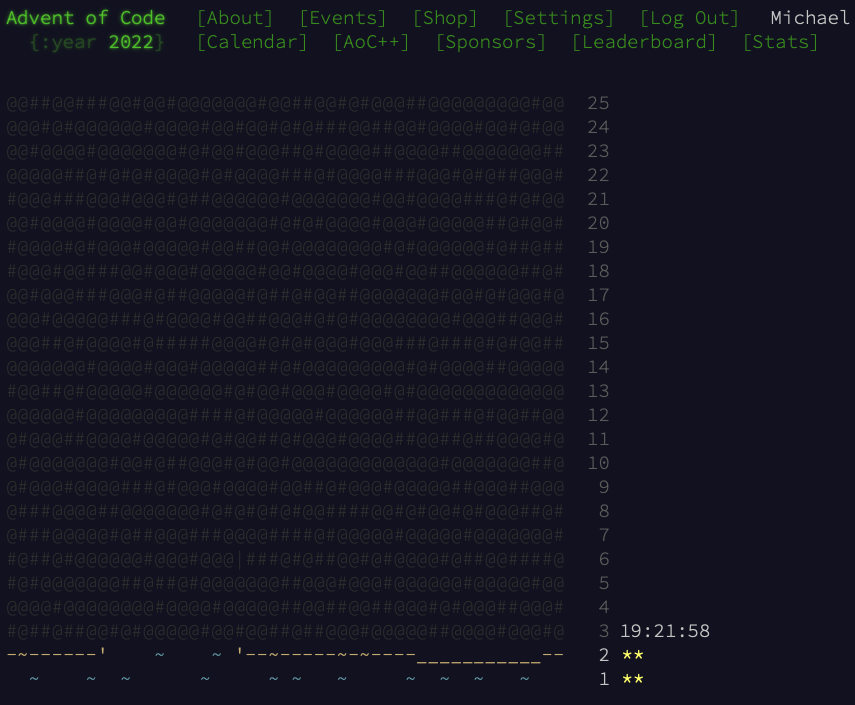
If you want to discover the rest of the image as the days go on, why not have a go at the puzzles yourself? It’s a great way to develop your problem solving skills!
Today’s Problem
Today we are playing games, good ole rock paper scissors specifically. The data input day forms a strategy guide.
In part 1 the first letter in the line tells us what the opponent plays: A for Rock, B for Paper and C for Scissors. The second letter is what we should play in response: X for Rock, Y for Paper and Z for Scissors. Score is a combination of the move we play (1 for Rock, 2 for Paper, 3 for Scissors) plus the outcome (0 for Loss, 3 for Draw, 6 for a Win).
Its time for a code snippet! C++ has a keyword called enum, short for Enumeration. It acts as a way to assign a human readable value to a number. For example:
enum MoveScores {
Rock = 1,
Paper = 2,
Scissors = 3
}
Many languages have enumerations, but the fun thing about C++’s is they can be converted directly to number values. This means my score calculation that would read:
score = 2 + 6;can read:
score = (int)Paper + (int)Win;This makes the code easier to understand. For AoC this might be a little bit overkill, as like I said on Day 1, speed is the most important thing. But it can be helpful to make your code easy to read, so when you have to make changes for part 2, it’s easier to work out.
To calculate part 1’s score, I simply wrote a loop to go line by line, figure out the score for that round using the logic explained above, and then added it to a running total.
For part 2 this time, the meaning of the second letter was changed, instead of being the move we play in response, it now represents our target outcome: X for a Loss, Y for a Draw and Z for a Win. This was pretty simple to do. I simply adjusted the inside part of the loop to reflect the new meaning. Instead of assuming X means Rock and comparing to the first letter, X now means Loss, so I look at the first letter and choose the correct response to lose the round. Score is calculated in the same way, so nothing needed to be changed there.
I hope this was interesting to read, and I look forward to updating again tomorrow! See you then.
As I feared, today did indeed have fangs! From now the puzzles will start to ramp up quite a lot in the time required to complete them. Therefore my entries to this post may become further spaced. AoC problems release for us in England at 4am, so I’m not always going to have enough time in the mornings to fully solve each puzzle.
Regardless, this was a fun problem to solve. It was the first place this year I decided to write some more extensible code, which lead me into doing some Object Oriented Programming, or OOP. Let’s explore!
Today’s Problem
The input today was a crazy one, representing a list of terminal commands and outputs. These commands map out a filesystem, and the size of each directory and file within it. The problem prompts us to find the sum size of all directories that are over 100,000 bytes in size.
An important thing to mention is this is a recursive problem. Take the directory paths C:/123/abc/456 and C:/123/abc/789 . The size of folder abc includes the size of everyone within 456 and 789. The size of folder 123 contains everything within 456, 789 and abc. Each directories size is equal to the total sum of EVERYTHING below it.
To solve this problem effectively, I decided to use a tree structure and write some classes to help structure the code. Let’s break each of those down.
The Tree
A tree is a data structure which starts with one item at the top. This item can then have multiple children, who can all have multiple of their own children etc. It is easy to understand when you see it drawn out.

Paddy3118, CC BY-SA 4.0, via Wikimedia Commons
As you can see in the diagram, it looks like the roots of a tree flipped upside down, hence the name.
Classes
Classes are an organisational structure, that allows us to write code that mirrors our real world understanding. For example I could define a class as:
class car {
int wheels = 4;
void drive();
}
The real power of this comes from being able to define children classes. For example I could have a new class called “Polo” that expands on the “Car” class, and adds new functions and data. This helps keep the code organised and closer to being human readable.
How it applies
Using the two ideas explained briefly above, I created a “File” class. It looks something like this (not complete)
class file {
FileType type;
int size;
file* parent;
list<file*> children;
}
FileType is an enumeration (explained in Day 2) that is either Directory or File. The parent and children variables are pointers, however I will not be explained those now as it will make this post to long. Alls that matter is that we use them to move from file to file.
After creating this class, I can create a single directory to represent the root of the file system. I can then loop the given instructions and create new directories and files as needed, with each new being added as a child to the correct entry. By the end of the problem input, I have a tree built of the entire filesystem, which can be accessed using the root directory object we first created.
For part 1, I walked through this tree and summed to a running total all directories that had a size of over 100,000 bytes.
For part 2 we had to find the smallest directory we could delete, to reach 30,000,000 bytes free. This simply required us to first find how much space is left (70,000,000 – size of root), find the difference between this and 30 million and then walk the tree again to find the smallest folder that is more than that amount.
Hopefully this wasn’t too mind boggling. See you again soon!